

















For every project, there are detailed product specifications setting out the task and objective. They also contain details from which the skills required can be derived. This enables project teams to be put together with great precision. The necessary information can be automatically extracted from the specifications using artificial intelligence.
Project duration and time-to-market are relevant parameters in industry, and these need to be optimized, because the longer a project runs, the higher the personnel expenses and the lower the competitiveness turn out to be. The focus is generally on improved production processes that mesh better and enable faster completion – in much the same way as manufacturing in a factory is optimized.
In this kind of analysis, the "preliminary work" is often overlooked. But the beginning of the development and manufacturing processes is not when a project starts: it starts with the project enquiry. When the product specifications are submitted, the important thing is to establish a project team to work through the tasks requested.
This is where things start to get interesting - because there is often untapped optimization potential here. Which department, which site is responsible for the project? What project team members are needed? Is there, in the company, specific know-how that is relevant to this project and can be used to avoid obstacles during implementation and enable access to developments that have already been successfully carried out? The right answers to these questions can have a major impact on the success of a project - but they are not easy to find. EDAG therefore addressed this problem in the course of an artificial intelligence (AI) research project.
Identifying the skills required
As a rule, a project order or project enquiry is based on product specifications. These contain essential information:- What needs to be done
- How this should be done
- Legal basis
- Time-related milestones
and a number of other details. The question as to what IT or engineering requirements apply is of particular relevance to the above-mentioned task. Specific mention is often made here of programming languages, frameworks, interfaces (APIs) and software tools which are to be used in application programming.
From an AI point of view, product specifications represent a document that generally has a certain structure using sections and subsections. The sections consist of text that can be evaluated using NLP (Natural Language Processing) techniques. It is the task of AI to find the relevant section describing the skills needed, and extract the information it contains.
From the job advertisement to product specifications
The research project was able to build on some preliminary work, as the description of the skills required is similar to a job advertisement - an area on which AI researchers have already focused. Nonetheless, unlike ordinary job advertisements which might, for instance, stipulate a degree in IT, requirements for IT or engineering-related skills are described in more detail in product specifications. This did, however, also mean that there are as yet no suitable gazetteers (i.e. lists of entity names) for the detailed IT skills. For this reason, the research project first involved creating a procedure for classifying relevant designations. The hard skills which emerged were divided into three categories:- Category 1: A certificate or degree in mechanical engineering, e.g. "Diplom-Ingenieur".
- Category 2: Knowledge of one field of work, e.g. experience in financial management and budgeting
- Category 3: A tool or API, e.g. software program such as Adobe Photoshop or programming languages such as C#.
The focus of the research project was therefore centered particularly on hard skills in the third category. They usually convey a better understanding of the skills required. In addition, the skill level can be specified on the basis of the hard skill, for instance "in-depth knowledge and experience in Corel Draw". Such skill levels are not the target of the original extraction process. They can, however, be useful for identifying abilities if they are part of the description.
A sentence-level analysis therefore seemed appropriate. Accordingly, the text analysis employed transformer models with an attention mechanism described by Vaswani et al., pre-trained with masked language modeling (MLM) and next sentence prediction (NSP). In this way, it was possible to use sentence structures and find the required skill targets.
Successful transformer models
Two different datasets were used for the research project. One was the Armenia dataset, a collection of English job advertisements from Armenia's Career Center from 2004 to 2015. These were divided into IT-related jobs and other jobs. The second dataset came from "AMT", EDAG's enquiry management tool. The only documents included from the latter were those that were available in PDF format and had a section, identified by its heading, with requirements relating to the skills being searched for. This dataset contains German texts only.
The evaluation was carried out on the basis of the BERT model (Bidirectional Encoder Representations from Transformers) developed by Devlin et al. When introduced, it achieved state-of-the-art accuracy. The model is designed to pre-train deep bidirectional representations from unlabeled text by conditioning left-to-right and right-to-left context together in all layers. This pre-trained set of the model can be fine-tuned for a wide range of tasks without making material task-specific changes to the architecture.
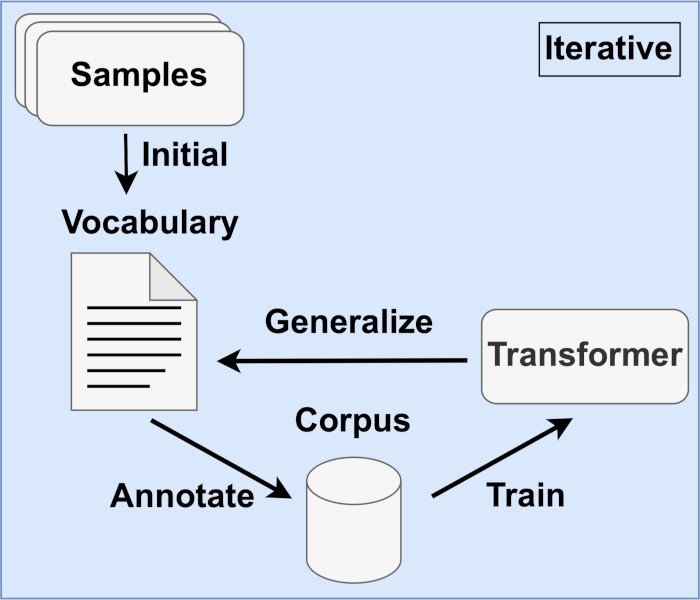
Representation of iterative training. Using an initially created skill list, the entire dataset can be automatically annotated to train the BERT model. The trained model is then able to identify new skills, and can therefore extend the skills list. The training process can be retriggered with the extended skill list.
The BERT model can also be put to multilingual use. In this case, two different transformer models - one for German and one for English - were coordinated. For the German AMT dataset, the pre-trained model bert-base-german-cased from deepset.ai was used. For the English Armenia IT dataset, use was made of the pre-trained roBERTa_base model. Both models were refined using the default parameters and the adaptive momentum estimation ADAM.
In the results, it can be seen that, on the basis of this research work, it was possible to develop a new type of extraction pipeline with regard to skill requirements. The pipeline is able to extract user-specific qualification requirements from job advertisements or requirements documents – for instance product specifications – in English or German. A test carried out on the pipeline using the Armenia-Other dataset showed that the process also works with other skill sets and therefore also in domains other than IT or engineering.
The introduced definition of the class labels differs from existing works. This definition enables the relevant skills to be pinpointed so that they are in line with subsequent processes such as management and planning. In computer science and engineering in particular, corresponding requirements for user competence occur more frequently.
AI in various applications
In large companies like EDAG, there are many different skills, and these can be found in different combinations at different sites. The paper presented makes it possible, as an initial step, for artificial intelligence to be used to automatically evaluate which skills are requested in product specifications. This makes it easier to put a suitable project team together.
Other forms of assistance are, however, also conceivable. The departments concerned or existing project teams might, for example, receive a kind of "skills fingerprint" to compare with the requirements profile of a new project, which would then quickly allow people to be assigned to the job. In this way, enquiries can quickly be assigned to the appropriate contacts, so customers receive a reply more promptly.
Another application would be to compare skill requirements from new product specifications with those from projects that have already been completed. Working on the assumption that if there is a high match in the skill profile, there is also likely to be a high match in the task assigned, it would then be easy to identify who already has the kind of experience that might be relevant to the new project.
EDAG is still considering how the results will be used in the future. Details of the classifier and transformation models that were used during the information extraction can be provided by Heiko Herchet, Vice President Digital Transformation. However, there are also numerous applications in which EDAG is already making use of artificial intelligence, for instance in image recognition and quality management. Another example is the AI-based optimization of industrial manufacturing. Our white paper "Edge Computing Brings AI into the Production Process" reveals how you, too, can benefit.





