

















The analysis of video data for the recognition of movement using artificial intelligence (AI) requires a lot of materials and energy. However, neural networks that are processing information via two different data streams deliver results of high accuracy with little effort. The EDAG research project furthermore offers optimization potential for industrial applications where image processing is a decisive factor.
A man enters the office, walks around the desk and stops, opens a notebook and makes entries; he then closes the notebook and sets it aside. Then he uses a measuring instrument and sits down in the office chair and finally starts a telephone conversation.
The colleague who watches him from her desk has no problem understanding what is going on at her colleague’s desk. For a computer this is a different ball game altogether. A computer has to be able to register and anticipate human movement to be capable of preventing collisions between autonomous vehicles and people in motion.
The computer not only needs to recognize the form of the human object but also its movement. And this can pose some difficulties. For example, when writing, merely the hands of a human body move. If a human uses a device, his or her torso will only move slightly, and the limbs will move more. When a human sits down in an office chair, the downward linear movement stops suddenly, and then the combination of a human and a chair will engage in joint movement.
Smart Rather than Strong
Artificial intelligence approaches so far have often led to resemble attrition warfare. Computational power and memory footprint continue to grow to dizzying levels to ensure that benchmarks are as consistent as possible with the pinpoints of accuracy and precision. Whenever investment capital and thus resources are limited, the time required for computation increases to such an extent that the recognition process does not allow for a real-time control system. A lot of energy is also required in both cases.
In the future, however, solutions are needed that are subject to a different set of requirements. For example, whenever in the smart city of tomorrow, a EDAG CityBot is taking care of parks or when a mobile robot is working together with human colleagues in a production facility. The energy consumption must then be limited, which means that compromises have to be made in terms of computational power and memory footprint without losing real-time capability; and this is exactly what a human observer would be able to do.
In the scope of research work at EDAG, this problem has been examined and valuable findings have been gained for practical application. The starting point was an AI model based on brain research because the processing of vision in the cerebral cortex of humans and other mammals has proven to work extremely efficiently. The implementation of the model delivered significantly improved results as compared to previous approaches. The applied methods have also been transferred to other AI approaches for image processing and they can be found not only on powerful computers but also on embedded platforms.
Two Pathways to Reach the Goal
Spatial vision, the identification of objects and their movements are capabilities processed in different areas of the brain. To this end, the visual system follows a hierarchical structure. Low level processing takes place in the early stages of the visual cortex while higher level processing occurs in the later stages. The sensory information from the eyes is first being pre-processed by the specialized section of the forebrain, the Nucleus Geniculatus Lateralis (NGL). Here, the information is split into separate streams for spatial and temporal information. The NGL then conveys these streams to the visual cortex where the information is further processed at a semantically higher level.
What caught the eye here was that the amount of spatial information was significantly larger than the amount of temporal information. Spatial recognition thus requires more precise information than the detection of movement. This is exactly the starting point of the applied “SlowFast” model, which has been developed by the facebook AI research group of Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik and Kaiming He.
This concept is used to describe a neural network that splits spatial and temporal information into two streams of data just like the human brain. The first “slow pathway” is based on a low sampling rate, used to capture image content according to categorical semantics. The second “fast pathway” stream is based on an analysis with a high frame rate, albeit a low detail resolution. The amount of data is reduced here by a factor of 5 as compared to the “slow pathway” stream. An essential element to achieve high-quality results are the connections between the two streams at the various levels of processing up to the point where the processes are joined at the end of the process.
The H.A.R.D. Architecture
The platform with a dual-stream neural network that is built according to this architecture primarily aims to reach the objective of detecting human movement in an uncontrolled environment referred to as Human Action Recognition & Detection, short H.A.R.D. The individual networks of the two separate streams should be sufficiently deep to enable the organization of hierarchical properties and the subdivision of individual stages into smaller blocks. Residual Neural Networks (ResNets) with 34 layers were thus chosen as they would satisfy said properties. However, rather than 2D Convolutional Neural Networks (CNNs), 3D CNNs were required to ensure the functional specialization of the individual streams.
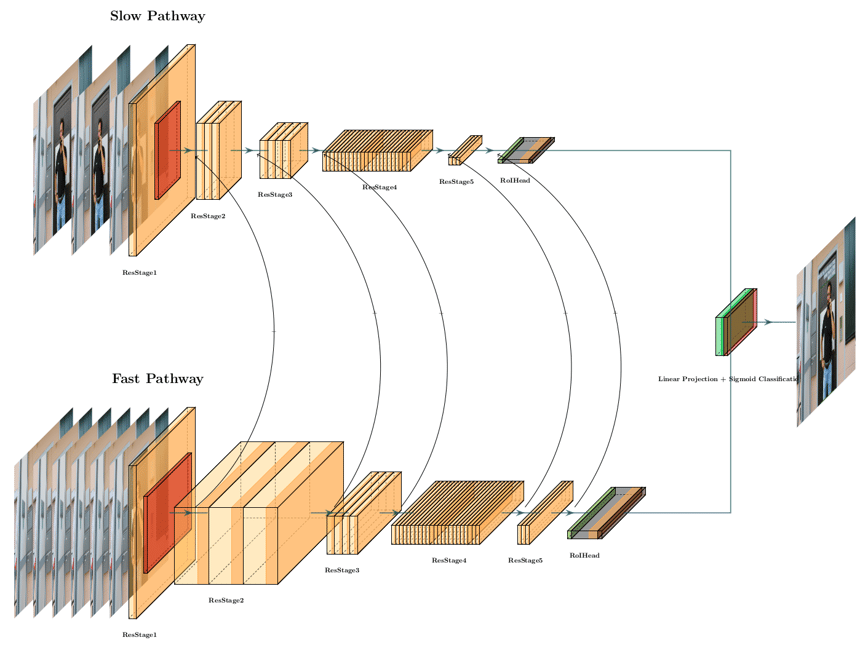
Schematic diagram of the H.A.R.D. architecture
The slow pathway in H.A.R.D. is implemented by a modified temporally strided 3D ResNet-101. In order to allow a signal to bypass one layer and move to a next layer in a sequence, shortcut connections are used. These shortcuts pass gradients through the network from early to later layers which allows to train very deep models, in our case comprising 101 layers.
A very deep architecture with hierarchical subdivisions is also chosen for the fast pathway. To guarantee a fine temporal representation, a small temporal stride with τ /α is chosen whereas α > 1 corresponds to the ratio between the frame rates of the fast pathway and the slow pathway. Since both pathways operate on the same raw data input, the fast pathway samples α times more frames than the slow pathway. The value of α > 1 guarantees that both pathways operate at different temporal speeds, ensures the specialization of neurons in the two pathways and thus is a key concept for SlowFast architectures.
In order to make the two separate pathways aware of what representation is learned by the other, information needs to flow between the two. This can be realized by fusing the two streams together according to the specific layers of the network via so called lateral connections. Using these lateral connections, the developers of the SlowFast model were able to surpass the state-of-the-art in movement detection.
High Efficiency with Little Effort
After successfully training and testing the model for movement recognition and detection, we evaluated the H.A.R.D. architecture on the basis of the AVA-Kinetics validation set. H.A.R.D. was able to increase the previous state-of-the-art performance by +7.3 mAP, resulting in a validation mAP of 28.2. When pretrained with Kinetics-600, the architecture could even improve its performance to 30.7 mAP (on version 2.2 of the AVA-Kinetics data set, which provides more consistent annotations). Here, mAP refers to the mean average precision, the average of the correct percentage according to the COCO guidelines.
Runtime cost is a deciding factor when deploying neural networks into practical applications. The total runtime cost per inference run for H.A.R.D is 7020 GFLOPS. And even though the SlowFast model consists of two separate 3D ResNet-101, it still has the lowest runtime cost with the second highest accuracy based on Kinetics-600.
However, accuracy and throughput are also decisive factors for deploying such models into production environments. Thus the accuracy per floating point operation is a crucial metric. The following illustration shows that the SlowFast approach achieves a top value in this discipline.
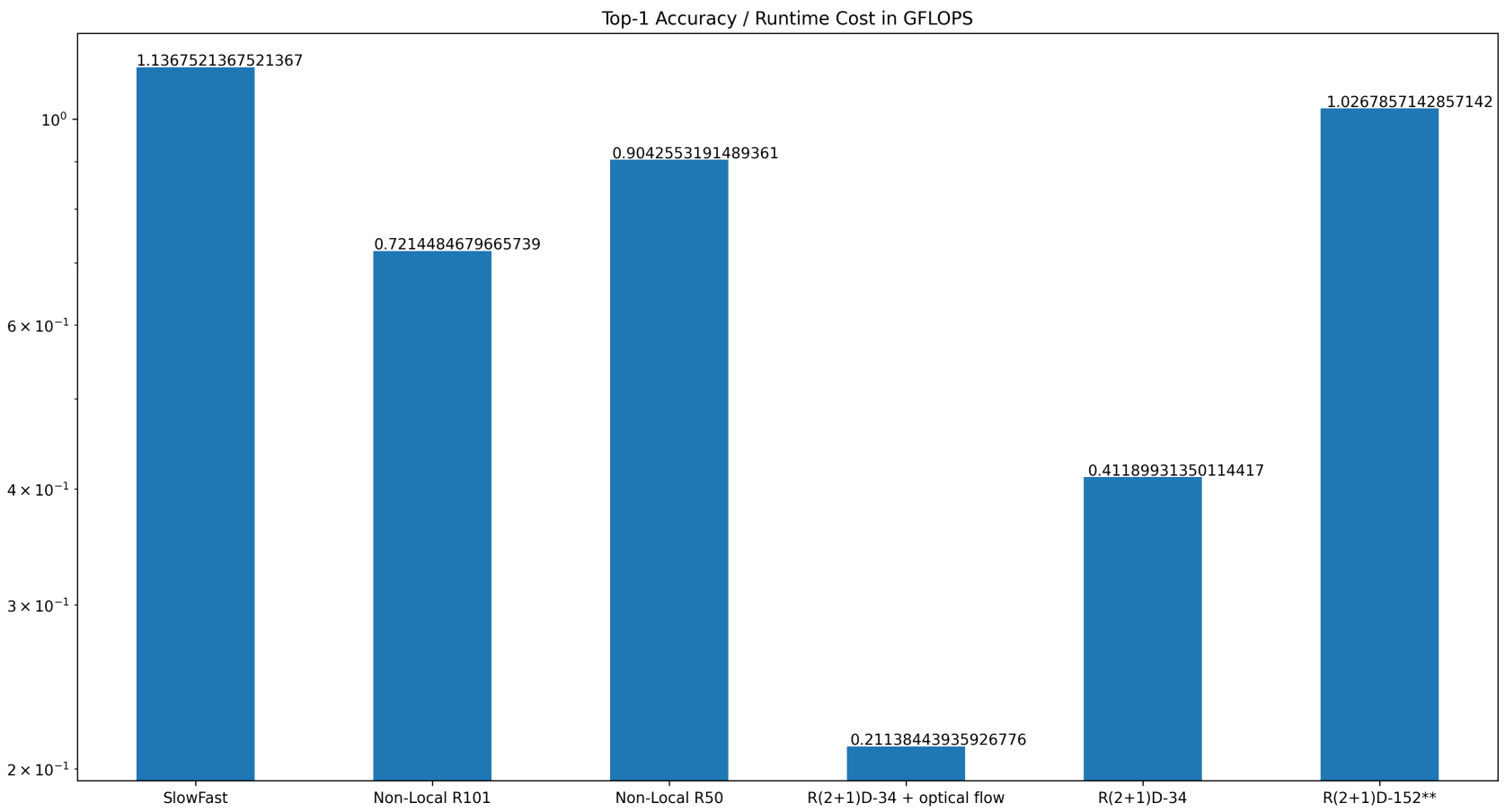
Accuracy per GFLOPS, higher values are better. (**) pre-trained on IG-65M
A hardware platform with 128 GPUs and a lot of memory were required for training the model. The application can be realized with a single GPU and thus is also suitable for use in embedded environments.
The Findings far Surpass H.A.R.D.
The results of the H.A.R.D. research project have not only substantiated the performance of the SlowPath approach. The findings gained also help to better understand the influence exerted by various factors on the process of image recognition and thus enable targeted optimization of the relevant neural networks. This does not only apply to the H.A.R.D. platform but also to the various convolutional neural network architectures used in image processing, for example, in the area of quality control where scratches or air pockets need to be detected under a coat of paint.
Wide range of applications in various industries
The H.A.R.D. architecture impressively demonstrates how AI-based image processing is not only becoming more efficient, but also more versatile - across all industries. In the medical environment, it can be used for the automated analysis of movement sequences in the operating room or for monitoring patients in intensive care - for example, to detect potentially dangerous changes in position. In rail transport, the technology enables the precise recording of movement sequences in stations or trains in order to detect safety-critical situations at an early stage. In production, it supports quality assurance by detecting the finest surface defects or automated activity analysis of employees in the assembly area.
Safety-relevant applications in the defence sector also benefit from the robust detection of complex movement scenarios - for example, for the automated detection of unusual behavior patterns in safety-critical zones. In the retail sector, the solution enables data protection-compliant analysis of customer movements to optimize walking routes or for automated people counting. Even in the construction industry - for example when monitoring safety-relevant movements on building sites - new automation potential can be tapped into thanks to the resource-saving approach.
These diverse use cases show how adaptive and powerful modern AI systems such as H.A.R.D. are. You can find a detailed look at specific application examples in the medical, rail, production, defense, retail and construction industries in our white paper "Efficient image processing using AI".
If you would like to know whether this AI model can be used to optimize your applications, please contact Heiko Herchet, Vice President Digital Transformation. Detailed information regarding the research project, the basics of brain research and the applied neural networks as well as a detailed look at specific application examples in the medical, rail, production, defense, retail and construction industries can be found in our white paper "Efficient image processing using AI". Download it now!





