

















Workshop orders, activity reports from service technicians or customer complaints – it is standard practice to document all of these in databases, along with the associated repair measures or other solutions. However, once the case is closed, the information stored is hardly ever accessed again. Even though it contains valuable practical knowledge. With the help of artificial intelligence, this knowledge can now, for the first time ever, be made accessible.
When a repair order in an auto repair shop says "clutch ped. jam", a human reader quickly realizes that this almost certainly means "clutch pedal jammed". However, things start to get difficult when the database is searched for all entries referring to the clutch pedal, especially if every mechanic uses his own short form.
And it gets even more complicated if, as a car manufacturer, you depart from the straightforward framework of a single repair shop and include the service tickets of all workshop partners, then add to these the entries of your own development engineers, and so bring together texts from countless authors all with different background knowledge. Potentially, there is a great deal of knowledge contained in short technical texts like those in a database driven ticket system or in the activity reports written by service technicians, and this could be profitably exploited.
It would, for example, be helpful to review recent instances of clutch pedals that have jammed to find out the most common causes and what solutions have proved successful, so that the problem does not recur. Yet spelling mistakes, inaccurate texts, the use of codes and abbreviations, and also multilingualism have so far made it virtually impossible to exploit this wealth of knowledge.
From Filing to Knowledge Repository
The automated analysis of texts is a task that can now be performed with good results using artificial intelligence. Here, a separate discipline has now emerged: natural language processing (NLP). The one thing this calls for, however, is a more or less natural language - and not the kind of abbreviated jargon given in the example above.
In a research project carried out in cooperation with Würzburg-based IT consultants "denkbares", EDAG Engineering has undertaken the task of turning the ticket database – until now little more than a record of tasks that have been completed – into a repository of knowledge from which users can benefit, as it will take them from the symptom to the root cause, and ultimately to a viable solution, more quickly. This means that young or new employees in particular, who can not yet look back on very many years of experience, can benefit from the know-how of others, instead of having to start from scratch with every finicky task and, by means of trial and error, work their way through all possible sources of errors.
Due to the above-mentioned problems with the existing database entries, the task had to be solved in two steps. First of all, the AI converts the source texts into a comprehensible form – and that means for the computer, too. Then it searches for semantically similar texts, to link these to the database entry. In use in a productive system, then, the car mechanic who enters "clutch ped. jam" would automatically be made aware of other possibly comparable tickets, for instance the entry "jammed cl.pedal".
Modular text preprocessing
To prepare the texts for further machine processing, EDAG and denkbares used a modular pipeline for text enhancement. Every module can be separately configured, executed and applied to the corresponding data. This guarantees rapid domain adaptation.
The first stage of text preprocessing is the "quality assessor", which performs two tasks. It checks whether the text can be processed by the pipeline: for instance whether the text is in a supported language. In addition, it also assesses whether the text contains any usable information at all. This is followed by the "normalizer" module, which deals, for instance, with the conversion of abbreviations into long forms, the processing of special characters and the correction of spelling errors.
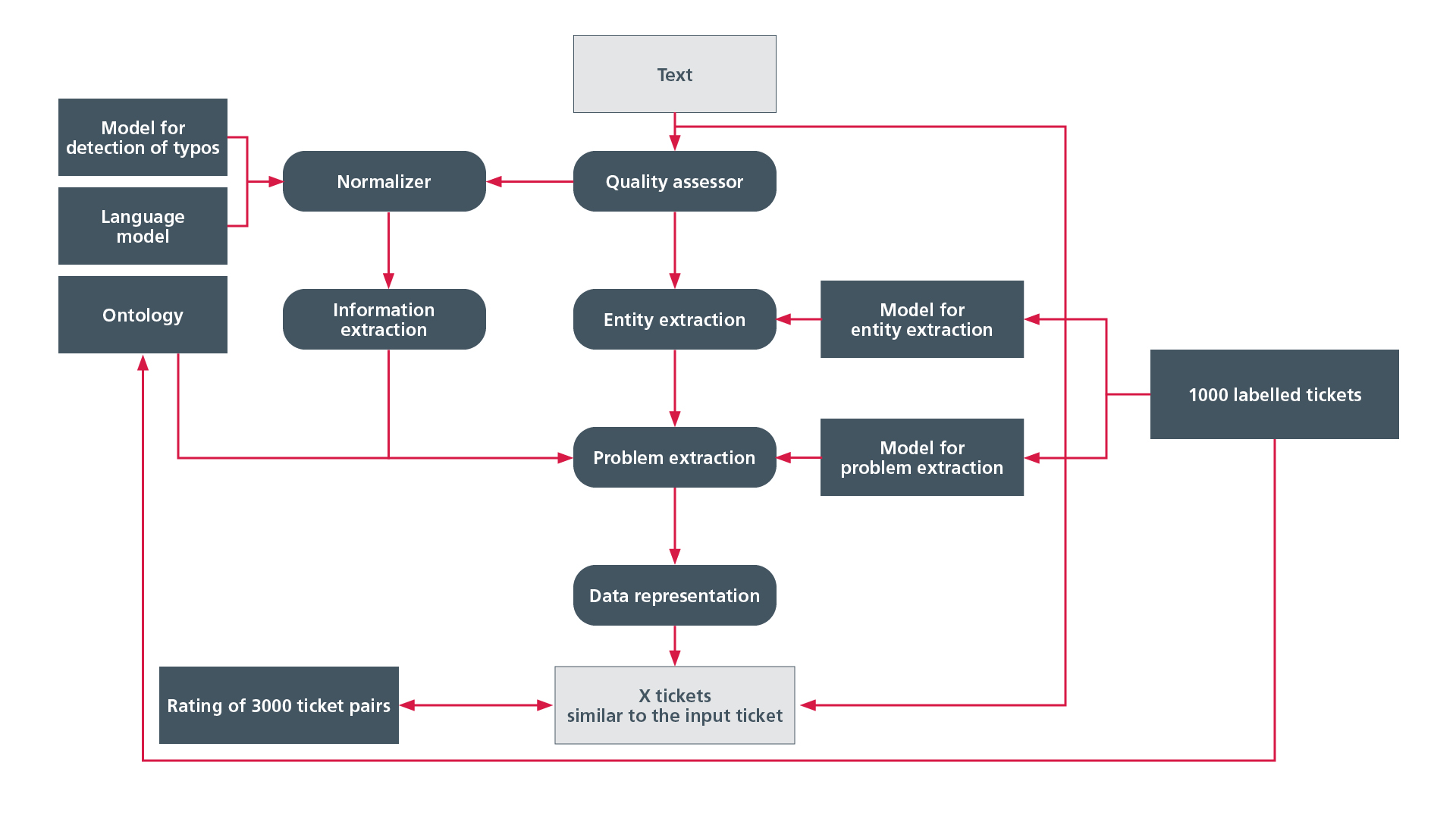
The "information extraction", "entity extraction" and "problem extraction" modules are responsible for filtering these out. In order to be able to contrast the respective advantages and disadvantages in practical use, the AI researchers pursued two approaches in parallel: the deep learning approach and the linguistic approach. Depending on which modules have been activated or deactivated, the evaluation is performed both ways or only for one approach or the other.
Advantages and disadvantages
Deep learning uses two neural networks. The first extracts error type, error location and error condition from the text entry, while the second classifies the ticket into one of 33 error classes.
The linguistic approach uses an ontology, which contains concepts and their relations to each other. One example of the relation is: a door handle is part of the door, the door is part of the vehicle body, the body is part of the vehicle. In this way, various types of information, for instance possible error types, error locations or the components used can be extracted, and the error class of the ticket determined.
One disadvantage of neural networks is that they cannot yet be fully explained, and so introduce a certain degree of uncertainty into the results. However, they have the advantage of being able to recognize entities they have not been trained to identify. It is therefore not necessary to include all relevant error types, locations and conditions in all conceivable orthographical variants in the training dataset.
And there lies the disadvantage of an ontology: it can only extract precisely those entities that are known. If just one letter is different, the entity will not be recognized. Its advantage is that it is fully transparent, and can therefore also be specifically extended. It is also possible here for relations and other properties of a concept to be represented. These can be helpful in the extraction of knowledge.
Encouraging results
To evaluate the "AIdentify" (artificial intelligence identify) pipeline developed by EDAG and denkbares, 1,000 labeled ticket pairs were generated. Three users were then each asked to label 100 test tickets in terms of their relations to ten other random tickets. The aim was for the most similar tickets to include as many ticket pairs as possible which, according to the evaluation, display a high degree of similarity with the input ticket. The evaluation standards used to assess the quality of the results were the factors precision and recall. Precision indicates the percentage of ticket pairs issued which, according to the users, are similar. Recall indicates the percentage of ticket pairs that, having been assessed by the users as displaying a high degree of similarity, are actually issued by the pipeline.
One success factor proved to be the representation of the tickets: either as plain text or as entities (meaningful items) with error class. The second case produced significantly better results. Also exciting was the comparison of the AIdentify pipeline and the Apache Software Foundation's Lucene open source full text search. In the recall range of 0.2 to 0.7 covered by AIdentify, the precision values were almost always higher; in a small range, both were almost equal.
A third comparison was carried out to determine how the ontological approach and deep learning approach differ. This also included a combination of the two analysis methods. The results are relatively clear: ontology only scored well in the range of low recall values (<0.27). The best results were almost always produced using neural networks, closely followed by the combined approach.
Ready for NLP usage
For two years, the research project "Artificial Intelligence for the Semantic Analysis of Short Technical Texts" (AIdentify) was funded by the Bavarian State Ministry for Economic Affairs, Regional Development and Energy within the framework of the Bavarian Joint Research Program (BayVFP), as part of the "Information and Communication Technology" R&D program. During this time, EDAG built up extensive natural language processing (NLP) skills.
The AIdentify pipeline developed by the EDAG Group and denkbares has now reached a good, functional level that permits the processing of various applications. On the basis of a ticket database, it is possible for country-specific defects in vehicles, trends in the automotive industry, or inconsistencies in the development of a vehicle, for example, to be identified. In addition, the pipeline's modular structure allows it to be adapted to other domains without excessive effort. Central points are an extended or newly created ontology and the adaptation of the neural networks. Auxiliary programs can be developed to create the classified data that will be needed here. One of the things the EDAG Group is currently working on is a method for semi-automatic ontology generation.
If you are planning a project in the field of NLP or have questions about EDAG's AI-related services, talk to our specialist Heiko Herchet, Vice President Digital Transformation. For more details about the AIdentify pipeline, its capabilities and results, please see our white paper.





