Zu jedem Projekt gibt es ein detailliertes Lastenheft, das Aufgabenstellung und Zielsetzung formuliert. Darin festgehalten sind auch Angaben, aus denen sich die benötigten Skills ableiten. So können zielgenau Projektteams zusammengestellt werden. Die nötigen Infos können automatisiert mittels Künstlicher Intelligenz aus dem Lastenheft extrahiert werden.
Projektlaufzeiten und Time-to-Market sind in der Industrie relevante Größen, die es zu optimieren gilt, denn je länger ein Projekt läuft, um so höher der Personalaufwand und umso geringer die Wettbewerbsfähigkeit. Im Fokus stehen dabei in der Regel verbesserte Produktionsprozesse, die besser ineinandergreifen und einen schnelleren Abschluss ermöglicht – ähnlich wie man die Fertigung in einer Fabrik optimiert.
Bei einer solchen Betrachtung fallen die „Vorarbeiten“ häufig durch das Raster. Doch ein Projekt startet nicht mit dem Beginn von Entwicklungs- und Fertigungsprozessen, sondern bereits mit der Projektanfrage. Wenn das Lastenheft eingereicht wird, gilt es, ein Projektteam zu etablieren, das die geforderten Aufgaben abarbeitet.
Bereits an dieser Stelle wird es interessant – denn hier schlummert ein bislang häufig nicht genutztes Optimierungspotenzial. Welche Abteilung, welcher Standort ist federführend im Projekt? Welche Mitglieder werden im Projektteam benötigt? Gibt es spezifisches Know-how im Unternehmen, das für dieses Projekt relevant ist und genutzt werden kann, um bei der Umsetzung Stolpersteine zu vermeiden und auf bereits erfolgreich eingesetzte Entwicklungen zurückgreifen zu können? Die richtigen Antworten auf diese Fragen können großen Einfluss auf den Projekterfolg nehmen – doch sie sind nicht leicht zu finden. EDAG hat sich dieses Problems daher im Rahmen einer Forschungsarbeit im Bereich Künstlicher Intelligenz (KI) angenommen.
Benötigte Fähigkeiten identifizieren
Ein Projektauftrag oder eine Projektanfrage stützen sich in der Regel auf ein Lastenheft. Das enthält wesentliche Informationen:- was gemacht werden soll;
- wie es gemacht werden soll;
- rechtliche Grundlagen;
- zeitliche Meilensteine
und etliche weitere Angaben. Für die oben genannte Aufgabenstellung ist vor allem relevant, welche Anforderungen in den Bereichen Informationstechnik oder Ingenieurswesen gestellt werden. Hier tauchen oft klar benannte Programmiersprachen, Frameworks, Schnittstellen (APIs) und Software-Tools auf, die bei der Anwendungsprogrammierung zum Einsatz kommen sollen.
Aus Sicht einer KI ist ein Lastenheft ein Dokument, das im Allgemeinen eine gewisse Struktur aus Abschnitten und Unterabschnitten aufweist. Die Abschnitte bestehen aus Text, der mittels NLP-Verfahren (Natural Language Processing) ausgewertet werden kann. Die Aufgabe der KI ist es, den relevanten Abschnitt mit der Beschreibung der benötigten Skills zu finden und die darin enthaltenen Informationen zu extrahieren.
Von der Stellenausschreibung zum Lastenheft
Die Forschungsarbeit konnte auf einige Vorarbeiten aufsetzen, denn die Beschreibung der benötigten Skills ist vergleichbar mit einer Stellenausschreibung – ein Gebiet, das KI-Forscher bereits in den Fokus genommen haben. Anders als in gewöhnlichen Stellenausschreibungen, die beispielsweise ein IT-Studium fordern, sind Anforderungen an IT- oder ingenieursbezogene Fähigkeiten in Lastenheften jedoch detaillierter beschrieben. Das bedeutete allerdings auch, dass es noch keine geeigneten Gazetteers (also Listen von Entitätsnamen) für die detaillierten IT-Skills gibt. Im Rahmen der Forschungsarbeit musste deshalb zunächst ein Verfahren zur Klassifikation relevanter Bezeichnungen erstellt werden. Die auftretenden Hard Skills wurden dabei in drei Kategorien eingeteilt:
- Kategorie 1: Ein Zertifikat oder Abschluss, z. B. Diplom-Ingenieur im Maschinenbau.
- Kategorie 2: Kenntnisse in einem Arbeitsbereich, z. B. Erfahrung im Finanzmanagement und in der Budgetierung.
- Kategorie 3: Ein Tool oder eine API, z. B. Softwareprogramme wie Adobe Photoshop oder Programmiersprachen wie C#.
Der Fokus der Forschungsarbeit lag daher insbesondere auf Hard Skills der dritten Kategorie. Sie vermitteln in der Regel ein besseres Verständnis der erforderlichen Kompetenzen. Darüber hinaus kann das Skill-Level anhand des Hard Skills spezifiziert werden, wie etwa „Starke Kenntnisse und Erfahrungen in Corel Draw“. Solche Fähigkeitsstufen sind nicht Ziel des ursprünglichen Extraktionsprozesses. Sie können aber bei der Erkennung von Fähigkeiten nützlich sein, wenn sie Bestandteil der Beschreibung sind.
Daher erschien eine Analyse auf Satzebene sinnvoll. Dementsprechend kamen bei der Textanalyse Transformatormodelle mit einem Aufmerksamkeitsmechanismus gemäß Vaswani et al. zum Einsatz, die mit Masked Language-Modeling (MLM) und Next Sentence Prediction (NSP) vortrainiert wurden. Auf diese Weise war es möglich, Satzstrukturen zu nutzen und die gewünschten Skillziele zu finden.
Erfolgreiche Transformatormodelle
Für die Forschungsarbeit wurden zwei unterschiedliche Datensets verwendet. Zum einen der Armenia-Datensatz, eine Sammlung englischsprachiger Stellenausschreibungen des Armenia's CareerCenter aus den Jahren 2004 bis 2015. Diese wurden aufgeteilt in IT-bezogene Stellen und andere Stellen. Der zweite Datensatz stammt aus dem „Anfragen Management Tool“ (AMT) von EDAG. Aus diesem wurden nur solche Dokumente einbezogen, die zum einen im Format PDF vorlagen, und zum anderen einen per Überschrift identifizierbaren Abschnitt mit Anforderungen zu den gesuchten Skills aufwiesen. Dieser Datensatz enthält ausschließlich deutschsprachige Texte.
Die Auswertung erfolgte auf Basis des BERT-Modells (Bidirectional Encoder Representations from Transformers), das von Devlin et al. entwickelt wurde. Es erreichte bei seiner Einführung eine Genauigkeit auf dem neuesten Stand der Technik. Das Modell ist so konzipiert, dass es tiefe bidirektionale Repräsentationen aus ungelabeltem Text vortrainiert, indem es den linken und rechten Kontext in allen Schichten gemeinsam konditioniert. Dieser vortrainierte Satz des Modells kann für eine breite Palette von Aufgaben ohne wesentliche aufgabenspezifische Änderungen der Architektur feiner abgestimmt werden.
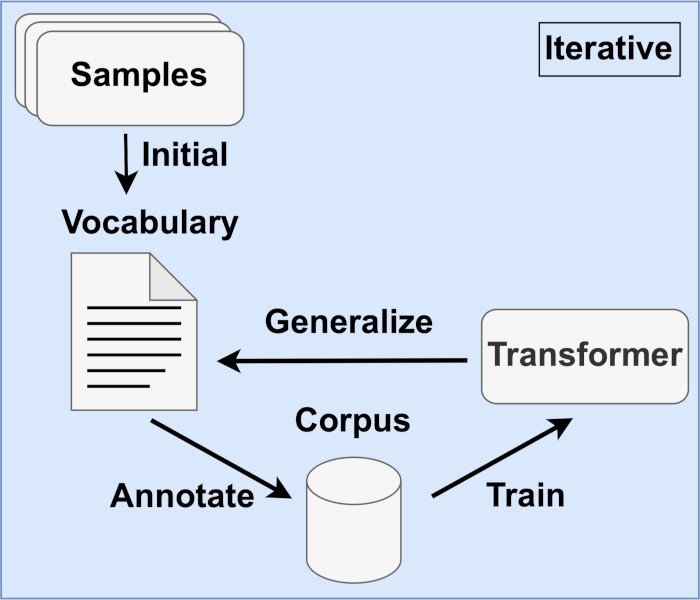 Darstellung des iterativen Trainings. Mittels einer anfänglich erstellten Skill-Liste kann der gesamte Datensatz automatisiert annotiert werden, um das Bert Modell zu trainieren. Das trainierte Modell ist dann in der Lage neue Skills zu identifizieren und kann damit die Skill-Liste erweitern. Mit der erweiterten Skill-Liste kann der Trainings-Prozess erneut angestoßen werden.
Darstellung des iterativen Trainings. Mittels einer anfänglich erstellten Skill-Liste kann der gesamte Datensatz automatisiert annotiert werden, um das Bert Modell zu trainieren. Das trainierte Modell ist dann in der Lage neue Skills zu identifizieren und kann damit die Skill-Liste erweitern. Mit der erweiterten Skill-Liste kann der Trainings-Prozess erneut angestoßen werden.
Das BERT-Modell kann auch mehrsprachig genutzt werden. In diesem Fall wurden zwei verschiedene Transformatormodelle jeweils für Deutsch und Englisch abgestimmt. Für den deutschsprachigen AMT-Datensatz kam das vortrainierte Modell bert-base-german-cased von deepset.ai zum Einsatz. Für den englischsprachigen Armenia-IT-Datensatz wurde auf das vortrainierte roBERTa_base-Modell zurückgegriffen. Beide Modelle wurden unter Verwendung der Standardparameter und der Adaptive Momentum-Schätzung ADAM verfeinert.
Im Ergebnis kann festgehalten werden, dass es auf Basis dieser Forschungsarbeit möglich war, eine neuartige Extraktionspipeline in Bezug auf Skill-Anforderungen zu entwickeln. Die Pipeline ist in der Lage, benutzerspezifische Qualifikationsanforderungen aus Stellenausschreibungen oder Anforderungsdokumenten – wie beispielsweise Lastenheften – in englischer oder deutscher Sprache zu extrahieren. Ein Test der Pipeline mit dem Datensatz Armenia-Other zeigte, dass das Verfahren auch mit anderen Skill-Sets und damit auch in anderen Domänen als IT bzw. Engineering funktioniert.
Die eingeführte Definition der Klassenlabel unterscheidet sich von bestehenden Arbeiten. Durch diese Definition können die relevanten Skills so eingegrenzt werden, dass sie nachfolgenden Prozessen wie Management und Planung entsprechen. Gerade in der Informatik und den Ingenieurwissenschaften treten entsprechende Anforderungen an die Benutzerkompetenz häufiger auf.
KI in unterschiedlichen Anwendungen
In großen Unternehmen wie EDAG gibt es viele unterschiedliche Fähigkeiten, die in unterschiedlichen Kombinationen an unterschiedlichen Standorten anzutreffen sind. Die vorliegende Arbeit ermöglicht in einem ersten Schritt, mittels Künstlicher Intelligenz automatisiert auszuwerten, welche Skills in einem Lastenheft gefordert werden. Das erleichtert die Zusammenstellung eines passenden Projektteams.
Jedoch sind auch weitere Hilfestellungen denkbar. So könnten die jeweiligen Abteilungen oder bereits vorhandene Projektteams eine Art „Skill-Fingerprint“ erhalten, der mit dem Anforderungsprofil eines neuen Projekts verglichen wird und so eine schnelle Zuweisung erlaubt. Auf diese Weise können Anfragen schneller den passenden Ansprechpartnern zugewiesen werden und die Kunden erhalten schneller Antwort.
Ein weiterer Anwendungsfall wäre ein Vergleich der Fähigkeiten-Anforderungen aus neuen Lastenheften mit denen von bereits abgeschlossenen Projekten. Unter der Annahme, dass bei einer hohen Übereinstimmung des Skill-Profils auch eine hohe Übereinstimmung der gestellten Aufgabe wahrscheinlich ist, könnte leicht ermittelt werden, wer bereits über entsprechende Erfahrung verfügt, die bei dem neuen Projekt möglicherweise von Belang ist.
Wie die Ergebnisse künftig eingesetzt werden, wird bei EDAG derzeit noch geprüft. Details zum Klassifikator und den Transformationsmodellen, die bei der Informations-Extraktion zum Einsatz kamen, kann Ihnen Heiko Herchet, Vice President Digital Transformation, geben. Doch es gibt auch zahlreiche Anwendungen, bei denen EDAG bereits Künstliche Intelligenz im Einsatz hat, beispielsweise im Bereich Bilderkennung und Qualitätsmanagement. Ein weiteres Beispiel ist die KI-basierte Optimierung der industriellen Fertigung. Wie auch Sie davon profitieren können, verrät unser Whitepaper „Edge Computing bringt KI in die Produktion“.





