Die Auswertung von Videodaten zur Erkennung von Bewegungen mittels Künstlicher Intelligenz (KI) erfordert hohen Aufwand an Material und Energie. Doch neuronale Netze, die Informationen in zwei unterschiedlichen Datenströmen verarbeiten, liefern Ergebnisse mit hoher Genauigkeit bei geringem Aufwand. Das EDAG-Forschungsprojekt eröffnet darüber hinaus Optimierungspotenziale für Anwendungen in der Industrie, bei denen die Bildverarbeitung entscheidend ist.
Ein Mann betritt das Büro, geht um den Schreibtisch herum, bleibt stehen, schlägt ein Notizbuch auf, nimmt Eintragungen vor, klappt das Notizbuch zu und legt es zur Seite. Dann bedient er kurz ein Messgerät, setzt sich danach auf den Bürostuhl und beginnt schließlich ein Telefongespräch.
Die Kollegin, die von ihrem Schreibtisch aus das Geschehen verfolgt, hat kein Problem zu erkennen, was dort vor sich geht. Ganz anders ergeht es einem Computer, der menschliche Bewegungen registrieren und prognostizieren soll, beispielsweise um Kollisionen eines autonomen Fahrzeugs mit sich bewegenden Personen zu verhindern.
Der Computer muss nicht nur das Objekt Mensch anhand seiner Form erkennen, sondern auch seine Bewegungen. Und da warten einige Schwierigkeiten: Beim Schreiben bewegen sich lediglich die Hände, bedient der Mensch ein Gerät, bewegt sich der Rumpf nur geringfügig, die Extremitäten dagegen mehr. Wenn der Mensch sich in den Bürostuhl setzt, wird die lineare Bewegung nach unten abrupt gestoppt, und dann bewegt sich die Kombination aus Mensch und Stuhl gemeinsam.
Schlau statt stark
Bisherige KI-Ansätze führen häufig zu einer Materialschlacht: Rechenpower und Datenspeicher wachsen in schwindelerregende Höhen, um in den Benchmarks dem Gipfel der Präzision möglichst nahe zu kommen. Wo Investitionsmittel und damit Ressourcen begrenzt sind, steigt die Rechenzeit derart an, dass die Erkennung für eine Echtzeitsteuerung nicht mehr ausreicht. In beiden Fällen werden zudem große Mengen Energie benötigt.
In Zukunft werden jedoch Lösungen benötigt, die anderen Anforderungen unterliegen. Beispielsweise wenn in der Smart City von morgen ein EDAG CityBot die Parkanlagen pflegt, oder wenn ein mobiler Roboter in der Fertigung Seite an Seite mit menschlichen Kollegen arbeitet. Dann muss der Energieverbrauch begrenzt werden, und das bedeutet Abstriche bei Rechenpower und Speicherplatz, ohne jedoch die Echtzeitfähigkeit zu verlieren – genauso, wie es einem menschlichen Beobachter möglich wäre.
Im Rahmen einer Forschungsarbeit hat man bei EDAG sich des Problems angenommen und dabei wertvolle Erkenntnisse für den praktischen Einsatz gewonnen. Ausgangspunkt war ein KI-Modell, das Anleihen bei der Hirnforschung nimmt, denn das Verarbeiten des Sehens in der Großhirnrinde von Menschen und anderen Säugetieren hat sich als extrem effizient erwiesen. Die Implementierung des Modells konnte noch deutlich bessere Ergebnisse liefern als vorangegangene Ansätze, und die dabei verwendeten Methoden sind auch für andere KI-Ansätze zur Bildverarbeitung übertragen – nicht nur auf dicken Rechnern, sondern auch auf Embedded-Plattformen.
Zwei Pfade zum Ziel
Räumliches Sehen, die Identifikation von Objekten und deren Bewegungen sind Fähigkeiten, die in unterschiedlichen Arealen unseres Hirns stattfinden. Das visuelle System ist dazu hierarchisch organisiert: es gibt eine Low-Level-Verarbeitung in den früheren und eine übergeordnete Verarbeitung in späteren Stadien des visuellen Trakts. Die sensorischen Informationen aus dem Auge werden zunächst im spezialisierten Teil des Vorderhirns, dem Nucleus geniculatum lateralis (NGL), vorverarbeitet. Hier werden die Informationen in separate Streams für räumliche und zeitliche Informationen aufgeteilt. Der NGL leitet diese Streams in den visuellen Kortex weiter, wo sie an unterschiedlichen Stellten auf einer semantisch höheren Ebene weiterverarbeitet werden.
Auffällig dabei: die räumlichen Informationen sind wesentlich umfangreicher als die zeitlichen Informationen. Die Erkennung des Raums braucht also genauere Informationen als die Erkennung von Bewegungen. Genau an dieser Stelle setzt das verwendete „SlowFast“-Modell an, das von der Facebook-KI-Forschergruppe Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik und Kaiming He entwickelt wurde.
Dieses Konzept beschreibt ein neuronales Netz, das wie im menschlichen Gehirn räumliche und zeitliche Informationen in zwei Datenströme auftrennt. Der erste, „slow path“ basiert auf einer niedrigen Abtastrate und dient der Erfassung der Bildinhalte nach einer kategorialen Semantik. Der zweite Stream, „fast path“, beruht auf einer Auswertung mit hoher Bildrate, aber geringer Detailauflösung – im Vergleich zum slow path ist hier die Datenmenge um den Faktor 5 geringer. Ein wesentliches Element für eine hohe Qualität der Ergebnisse sind Verbindungen zwischen den beiden Streams auf verschiedenen Ebenen der Verarbeitung, bis hin zur Vereinigung am Ende des Prozesses.
Die H.A.R.D.-Architektur
Die darauf aufbauende Plattform mit einem zweiströmigen neuronalen Netz dient vorrangig dem Ziel der Erkennung menschlicher Bewegungen in freier Wildbahn: Human Action Recognition & Detection, kurz: H.A.R.D. Die einzelnen Netze der beiden separaten Ströme sollten eine ausreichende Tiefe aufweisen, um hierarchische Eigenschaften sowie die Untergliederung der einzelnen Stufen in kleinere Blöcke zu ermöglichen. Es wurden Redidual Neuronal Networks (ResNets) mit 34 Schichten gewählt, da diese Netze diese geforderten Eigenschaften erfüllen. Allerdings waren statt 2D Convolutional Neuronal Networks (CNN) 3D-Convolutions erforderlich, um die funktionale Spezialisierung der einzelnen Ströme sicherzustellen.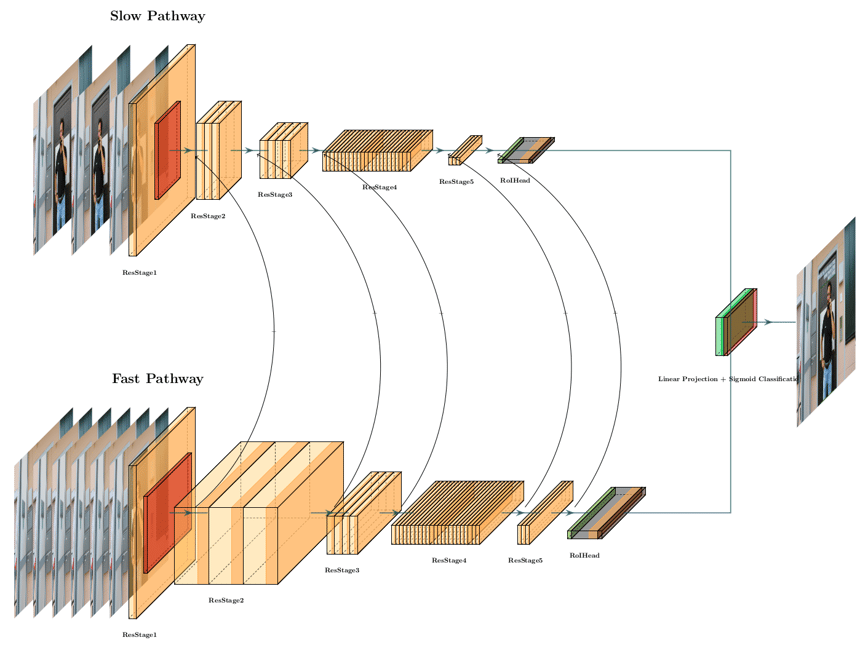
Schematische Darstellung der H.A.R.D. Architektur
Der langsame Pfad im H.A.R.D. wird mithilfe eines modifizierten 3D ResNet-101 mit zeitlichen Schritten implementiert. Damit ein Signal eine Schicht umgehen kann und zur nächsten Schicht einer Sequenz übergehen kann, werden so genannte Shortcut Connections verwendet. Diese Abkürzungen verlaufen über Gradienten durch das Netz von früheren zu späteren Schichten, was das Trainieren tiefer Modelle ermöglicht, in unserem Falle bestehend aus 101 Schichten.
Auch im schnellen Pfad wird eine sehr tiefe Architektur mit hierarchischen Unterteilungen gewählt. Um eine feine zeitliche Darstellung zu gewährleisten, wird ein kleiner zeitlicher Schritt mit τ /α gewählt. Dabei entspricht α > 1 dem Verhältnis zwischen den Frameraten des schnellen zum langsamen Pfad. Da beide Pfade auf demselben Rohdaten-Input arbeiten, tastet der schnelle Pfad α Mal mehr Frames ab als der langsame. Der Wert von α > 1 gewährleistet, dass beide Pfade mit unterschiedlichen zeitlichen Geschwindigkeiten arbeiten und stellt zudem die Spezialisierung von Neuronen in den beiden Pfaden sicher. Insofern handelt es sich hierbei um ein Schlüsselkonzept für SlowFast-Architekturen.
Zwischen den beiden separaten Pfaden müssen Informationen fließen. Nur so kann der eine Pfad „wissen“, welche Darstellung vom jeweils anderen Pfad „erlernt“ wird. Dazu werden die beiden Ströme nach spezifischen Schichten des Netzes über so genannte laterale Verbindungen miteinander fusioniert. Mithilfe dieser lateralen Verbindungen ist es den Entwicklern des Slowfast-Modells gelungen, den Stand der Technik im Bereich der Bewegungserfassung zu überholen.
Hohe Effizienz mit geringem Aufwand
Nachdem das Modell zunächst hinsichtlich der Erkennung und Erfassung von Bewegungen erfolgreich trainiert und getestet wurde, haben wir die H.A.R.D.-Architektur auf Basis des AVA-Kinetics-Validierungsdatensatzes evaluiert. Mit einem Validierungsergebnis von 28,2 mAP ist es H.A.R.D. gelungen, die Performance gemäß früherem Stand der Technik um +7,3 mAP zu übertreffen. Wenn die Architektur vorab mit Kinetics-600 trainiert wurde, konnte sie ihre Performance sogar auf 30,7 mAP verbessern (Version 2.2 des AVA-Kinetics Datensatzes, der konsistentere Annotationen liefert). Hier bezieht sich die Einheit mAP auf den arithmetischen Mittelwert der Präzision, d.h. den Mittelwert des gemäß COCO-Leitlinien korrekten Prozentsatzes.
Beim Einsatz neuronaler Netze in praktischen Anwendungen sind die Laufzeitkosten ein entscheidender Faktor. Beim H.A.R.D betragen die Gesamt-Laufzeitkosten pro Interferenzlauf 7020 GFLOPS. Und obwohl das SlowFast-Modell zwei separate 3D ResNet-101 umfasst, hat es immer noch die geringsten Laufzeitkosten in Kombination mit der zweithöchsten Präzision basierend auf Kinetics-600.
Für den Einsatz solcher Modelle in Produktionsumgebungen sind jedoch auch Präzision und Durchsatz ausschlaggebende Faktoren. Somit ist die Präzision pro Gleitkommaoperation eine sehr wichtige Metrik. Die folgende Abbildung zeigt, dass der SlowFast-Ansatz in dieser Disziplin einen Spitzenwert erzielt.
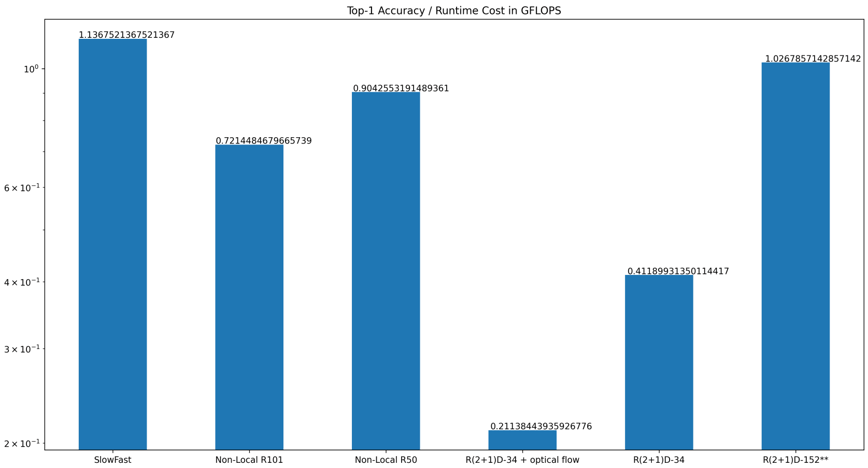
Präzision pro GFLOPS, höhere Werte sind besser. (**) wurde vortrainiert auf IG-65M
Um das Modell zu trainieren, war eine Hardwareplattform mit 128 GPUs und entsprechend viel Datenspeicher notwendig. Die Anwendung selbst lässt sich jedoch mit einer einzelnen GPU realisieren und ist somit auch für den Einsatz in Embedded-Umgebungen geeignet.
Erkenntnisse reichen über H.A.R.D. hinaus
Das H.A.R.D.-Forschungsprojekt belegte jedoch nicht nur die Leistungsfähigkeit des SlowPath-Ansatzes. Die gewonnenen Erkenntnisse tragen dazu bei, den Einfluss unterschiedlicher Faktoren auf die Performance der Bilderkennung besser zu verstehen, und ermöglichen daher, entsprechende neuronale Netze gezielt zu optimieren. Das gilt nicht nur für die H.A.R.D.-Plattform, sondern auch für unterschiedliche CNN-Architekturen, also Convolutional Neuronal Networks, die zur Bildverarbeitung verwendet werden, etwa bei der Qualitätskontrolle, wo beispielsweise Kratzer oder Lufteinschlüsse unter dem Lack aufzuspüren sind.
Vielfältige Anwendungsfälle in verschiedenen Branchen
Die H.A.R.D.-Architektur zeigt eindrucksvoll, wie KI-basierte Bildverarbeitung nicht nur effizienter, sondern auch vielseitiger einsetzbar ist – und das branchenübergreifend. Im medizinischen Umfeld kann sie zur automatisierten Analyse von Bewegungsabläufen im Operationssaal oder zur Überwachung liegender Patienten in der Intensivpflege genutzt werden – etwa zur Erkennung potenziell gefährlicher Positionsveränderungen. Im Schienenverkehr ermöglicht die Technologie die präzise Erfassung von Bewegungsabläufen in Bahnhöfen oder Zügen, um sicherheitskritische Situationen frühzeitig zu erkennen. In der Produktion unterstützt sie bei der Qualitätssicherung durch die Detektion feinster Oberflächenfehler oder automatisierte Tätigkeitsanalyse von Mitarbeitenden im Montagebereich.
Auch sicherheitsrelevante Anwendungen im Defence-Bereich profitieren von der robusten Erkennung komplexer Bewegungsszenarien – etwa zur automatisierten Erkennung ungewöhnlicher Verhaltensmuster in sicherheitskritischen Zonen. Im Einzelhandel ermöglicht die Lösung eine datenschutzkonforme Analyse von Kundenbewegungen zur Optimierung von Laufwegen oder zur automatisierten Personenzählung. Selbst im Bauwesen – beispielsweise bei der Überwachung sicherheitsrelevanter Bewegungen auf Baustellen – lassen sich durch den ressourcenschonenden Ansatz neue Automatisierungspotenziale erschließen.
Diese vielfältigen Use Cases zeigen, wie adaptiv und leistungsfähig moderne KI-Systeme wie H.A.R.D. sind. Eine detaillierte Betrachtung konkreter Anwendungsbeispiele in den Branchen Medical, Rail, Produktion, Defence, Einzelhandel und Bauwesen finden Sie in unserem Whitepaper „Effiziente Bildverarbeitung mittels KI“.
Wenn Sie wissen wollen, ob dieses KI-Modell auch Ihre Anwendungen optimieren kann, sprechen Sie mit Heiko Herchet, Vice President Digital Transformation. Weitere Details zum Forschungsprojekt, den Grundlagen der Hirnforschung und den eingesetzten neuronalen Netzwerken sowie eine detaillierte Betrachtung konkreter Anwendungsbeispiele in den Branchen Medical, Rail, Produktion, Defence, Einzelhandel und Bauwesen finden Sie in unserem Whitepaper „Effiziente Bildverarbeitung mittels KI“. Laden Sie es sich gleich herunter!





