

















Artificial intelligence (AI) is being used in more and more areas of life and business. If it had not already happened before, it was the discussion about ChatGPT that finally confronted the general public with the question of the reliability and quality of the results of AI. The problem has, however, long been the subject of research, since solutions are needed as urgently as the AI applications themselves.
In the last few weeks, an intelligent ChatBot has been causing a sensation. The idea is that it should be possible to talk with ChatGPT as if it were a real human being. The AI model is also able to write complete articles or even program codes if instructed to do so. What really caused a stir, however, were the weaknesses of the AI model. Not only did it occasionally mix up facts, it was also found to simply make them up, along with references that either proved to be non-existent or had no factual connection to the statement they were allegedly substantiating.
The basic problem behind the story is: can you trust AI? Which in turn gives rise to the question of the extent to which it is possible to check or measure the quality of the results provided by an AI model. Especially with self-learning algorithms based on neural networks, the decisions of artificial intelligence ultimately originate from a black box – and can therefore not easily be comprehended.
Making AI comprehensible
In addition to the growing use of machine learning (ML), the problem is aggravated by the sharp increase in the number of storage and computing resources available. As a result, the amount of data used is growing exponentially, making it increasingly difficult to establish a connection between the input and output of the AI system.
And yet this is the one thing that is essential: to create transparency in a system which to begin with is unclear. In other words: to make a black box model into a white box model by creating clarity. Only when the people developing an AI model know how the system arrives at its results can they systematically influence the key areas and improve the quality of the output.
On the other hand, there are also legal requirements. The legal framework for artificial intelligence passed by the EU Commission in 2021 requires, for instance, that decisions by an AI system must be transparent and clear. The aim of the EU is to prevent the rejection of an application for credit, for example, being justified by means of a simple reference to a computerized "colleague".
Different ways to achieve a goal
The EDAG Group recognized the potential of artificial intelligence at an early stage and, in a wide variety of areas, is involved in the development of AI models for different fields of application, as can be seen from the overview given here. Machine learning concepts and neural networks play a significant role in the process. The EDAG developers are paying particularly attention to the fields of image recognition and improvement for object recognition via smartphone, for example, and text analysis using NLP (natural language processing) techniques. The latter, for example, culminated in projects aimed at extracting information from project descriptions and specifications or activating the knowledge contained in service tickets.
At least superficially, it is easy to check the results of an AI model in the field of image processing, because the human observer can clearly see whether an object has been recognized and/or correctly classified. In other words: the target result is known, discrepancies can be easily detected and therefore quantified. Text analysis, however, is a very different matter: Here, it is difficult to tell how many service tickets from an extensive database are actually relevant to a certain subject, and what percentage of these the AI model has found.
In "Explainable Artificial Intelligence for Natural Language Processing" (or XAI 4 NLP), the Bachelor's thesis she wrote at EDAG, Laura Paskowski examined various different approaches that might be used to bring transparency to AI models in the field of text analysis. In addition, she also looked into the question of how improvements to the AI models might be derived from this. Throughout, she confined herself to local results, i.e. the explainability of special AI predictions, and not the overall (global) decision-making process. Further, it is possible to distinguish between the different approaches depending on the question of how and when the explanation arises. "Self-explaining / model-specific" are models which generate the explanation while they are working. In this case, XAI requires knowledge of the internal processes or the structure of the AI model. With a post-hoc / model-agnostic strategy, the explanation is generated after the AI model has made a prediction. In this case, no knowledge of the internal processes or the structure of the AI model is required.
Four approaches under close observation
The "local interpretable model-agnostic explanation (LIME)" approach is based on the premise that various partial results are explained with the help of so-called surrogate models, i.e. simplified models, and in this way approach the overall result.
Layer-wise relevance propagation (LRP) operates by means of the back propagation of the output through the network. This involves taking the result and going back several layers in the neural network, then looking at the respective relevance values R. These are calculated by means of activation and weighting. In this way, the attempt is made to find out the extent to which each input word contributed to the prediction on the one hand, and what contribution each neuron made to the decision.
DeepLIFT (Deep Learning Important FeaTures) is another approach. This, too, is based on back propagation through the network. But in contrast to LRP, this method works using contribution scores for the neurons. These are calculated by systematically activating the neurons, which react with different results to different inputs – an original input and a reference input.
The technique of using integrated gradients (IG) to explain a decision is based on a comparison of a neutral baseline as the input and the original input. Starting from the baseline – in the field of image processing, this would be a black surface – the inputs slowly approach the original input. Along this path, the AI model is used for every point, and a gradient is calculated. The integrated gradients are calculated on the basis of an integral of the gradients along the path. In this way, it is possible, by means of interpolation, to find out which words are critical for the prediction of the AI model.
Practical Application
In a further step, Laura Paskowski investigated the question of how these XAI approaches create greater transparency in the results when information is extracted from project descriptions and product specifications, and might therefore be used to further improve the underlying AI model. The task of this AI model is to use NLP to find out from project enquiries or product specifications which competencies are centrally required, and on this basis decide which department or contact partner is to be assigned the further processing. This should help to reduce the number of errors and improve response time for the customer.
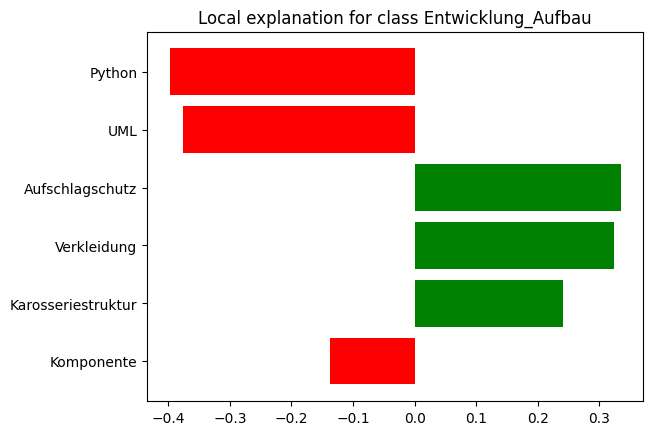
As a result, the various different XAI approaches supply a list of keywords for each output class, with the appropriate weighting: high influence, low influence or neutral. After training an AI model on the basis of machine learning, these weightings are initially unknown. With XAI, however, it is possible to translate the classification of the AI into a "keyword fingerprint", which in turn can be examined to see whether the keywords contained, or their weighting, are in line with the expected result. On this basis, the AI model can be specifically adjusted to improve the quality of the predictions.
Supplying and documenting quality
It is a matter of critical importance to EDAG's AI team that they should be able not only to offer their customers AI models for practical applications, but also to explain the results. It is not enough simply to develop an AI model that produces useful results. It is also essential to evaluate these results, in order to be able to make quality-related statements. Explainable artificial intelligence provides the tools to do this.
This is the only way to identify the kind of misinterpretations of the AI that occurred in an experiment to distinguish between different animals. Although the model worked very well with the learning data, it failed when new, unknown images were input. Ultimately, it transpired that the AI had not distinguished between the actual objects – the animals depicted – but instead, recognition after the ML training was based entirely on the different backgrounds, which by chance happened to correlate with the animals.
And for the further development of the models, the enhancement of the input or improvement of the output for instance, it is essential to understand how the AI model works. The point of this is to help build the customers' confidence in both the practicality of the AI models developed by EDAG and the abilities of the company's AI experts.
Further information on the use and quality assurance of AI models in NLP projects can be obtained from Heiko Herchet, Vice President Digital Transformation. The white paper "From Ticket Filing to Knowledge Repository with AI" also explains in detail how, in an NLP project, AI can help to activate untapped knowledge in your own company. Download it here.





