Werkstatt-Aufträge, Einsatzberichte von Service-Technikern oder Kundenreklamationen – sie alle werden standardmäßig in Datenbanken dokumentiert, ebenso die damit verbundenen Reparaturmaßnahmen oder sonstigen Lösungen. Doch ist der Fall geschlossen, wird auf die gespeicherten Informationen kaum noch zugegriffen. Dabei enthalten sie wertvolles Praxiswissen. Mit Hilfe Künstlicher Intelligenz kann das nun erstmals zugänglich gemacht werden.
Wenn in einer Autowerkstatt als Reparaturauftrag „Kuppl.Ped. klemt“ auftaucht, dann ist einem menschlichen Leser schnell klar, dass damit mit ziemlicher Sicherheit „Kupplungspedal klemmt“ gemeint ist. Schwierig wird es allerdings, wenn man die Datenbank nach allen Einträgen durchsuchen will, die sich auf das Kupplungspedal beziehen, vor allem dann, wenn jeder Mechaniker seine eigene Kurzform verwendet.
Noch komplizierter wird es, wenn man den überschaubaren Rahmen einer einzelnen Werkstatt verlässt und als Autohersteller auf die Service-Tickets aller Werkstattpartner blickt, und diese auch noch um die Einträge der eigenen Entwicklungsingenieure erweitert, also Texte unzähliger Autoren mit unterschiedlichem Hintergrundwissen zusammenbringt. Potenziell schlummert in solchen technischen Kurztexten, wie eben in einem Datenbank-basierten Ticket-System oder in den Einsatzberichten von Servicetechnikern eine Menge Erfahrungswissen, das sich gewinnbringend erschließen ließe.
Es wäre beispielsweise hilfreich, die letzten Fälle von klemmenden Kupplungspedalen zu überprüfen, um zu sehen, was die häufigsten Ursachen waren und welche Lösungen sich bewährt haben, so dass das Problem nicht erneut auftritt. Doch Rechtschreibfehler, fehlerhafte Texte, Verwendung von Codes und Abkürzungen sowie Mehrsprachigkeit machen es bislang nahezu unmöglich, diesen Wissensschatz zu heben.
Von der Ablage zum Wissensspeicher
Die automatisierte Auswertung von Texten ist eine Aufgabe, die inzwischen mit guten Ergebnissen mittels Künstlicher Intelligenz erledigt werden kann. Hier hat sich eine eigene Disziplin herausgebildet: Natural Language Processing (NLP), also die Verarbeitung natürlicher Sprache. Voraussetzung ist aber eben eine einigermaßen natürliche Sprache – und nicht das Abkürzungs-Kauderwelsch wie im obigen Beispiel.
Im Rahmen eines Forschungsprojekts gemeinsam mit der IT-Beratung „denkbares“ aus Würzburg hat EDAG Engineering sich der Aufgabe angenommen, aus der Ticket-Datenbank, die bislang kaum mehr war als eine Dokumentation der erledigten Aufgaben, einen Wissensspeicher zu machen, von dem die Nutzer profitieren können, indem sie schneller von Symptom zur eigentlichen Ursache und schließlich zu einer tragfähigen Lösung kommen. So profitieren insbesondere jüngere oder neue Mitarbeiterinnen und Mitarbeiter, die noch nicht auf eigene langjährige Erfahrungen bauen können, vom Know-how anderer, anstatt bei jeder kniffligen Aufgabe erneut im Trial&Error-Verfahren von Null zu beginnen und sich durch alle möglichen Fehlerquellen durchzuarbeiten.
Aufgrund der beschriebenen Probleme bei den vorgefundenen Datenbank-Einträgen musste die Aufgabe in zwei Schritten gelöst werden. Zunächst werden die Ausgangstexte von der KI erst einmal in eine – auch für den Computer – verständliche Form gebracht. Danach sucht sie semantisch ähnliche Texte, um sie mit dem Datenbankeintrag zu verknüpfen. In ein Produktivsystem implementiert, würde also der Automechaniker, der „Kuppl.Ped. klemt“ einträgt, automatisch auf weitere möglicherweise vergleichbare Tickets aufmerksam gemacht, etwa einen Eintrag „verklemm. Kupplungsp.“
Modulare Textvorverarbeitung
Um die Texte für die maschinelle Weiterverarbeitung vorzubereiten, setzte man bei EDAG und denkbares auf eine modulare Pipeline zur Textverbesserung. Jedes Modul für sich ist konfigurierbar, ausführbar und auf die entsprechenden Daten anwendbar. So wird eine schnelle Domänenanpassung garantiert.
Erster Schritt der Textvorverarbeitung ist der „Quality Assessor“, der zwei Aufgaben erfüllt. Er überprüft, ob der Text von der Pipeline verarbeitet werden kann, beispielsweise ob der Text in einer unterstützten Sprache vorliegt. Zum anderen stellt er fest, ob in dem Text überhaupt verwertbare Informationen enthalten sind. Daran schließt sich das Modul „Normalizer“ an. Dieses erledigt beispielsweise die Überführung von Abkürzungen in Langformen, die Verarbeitung von Sonderzeichen und die Korrektur von Rechtschreibfehlern.
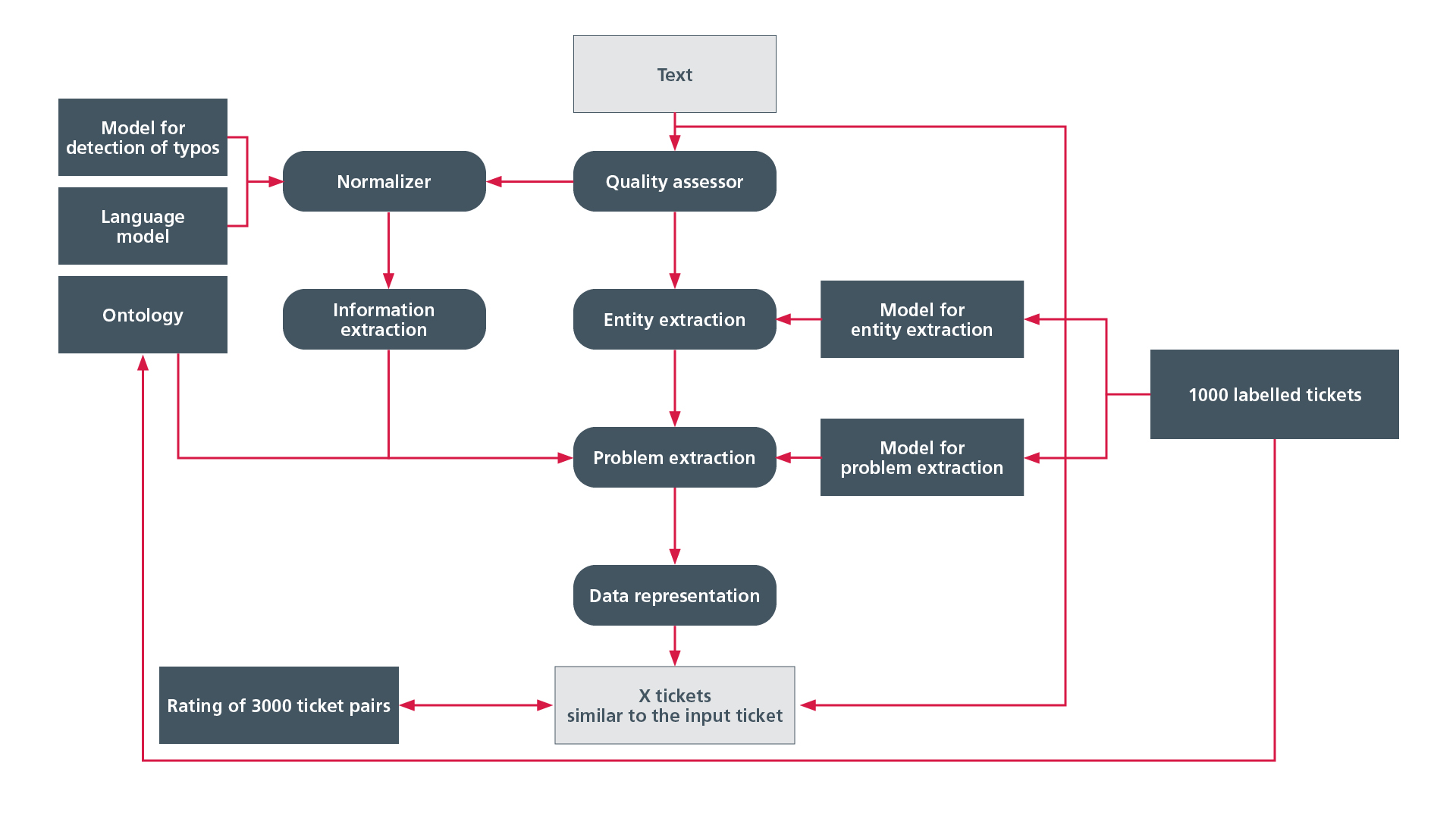
Diese herauszufiltern übernehmen die Module „Information extraction“, „Entity extraction“ und „Problem extraction“. Um die jeweiligen Vor- und Nachteile im praktischen Einsatz gegenüberstellen zu können, verfolgten die KI-Forscher zwei Ansätze parallel: den Deep-Learning-Ansatz und den linguistischen Ansatz. Je nachdem, welche Module aktiv oder deaktiviert sind, erfolgt die Auswertung auf beiden Wegen oder jeweils nur nach dem einen oder dem anderen Ansatz.
Vor- und Nachteile
Beim Deep Learning kommen zwei neuronale Netze zum Einsatz. Das erste extrahiert Fehlerart, Fehlerort und Fehlerbedingung aus dem Texteintrag, das zweite klassifiziert das Ticket in eine von 33 Fehlerklassen.
Im linguistischen Ansatz wird mit einer Ontologie gearbeitet; diese beinhaltet Konzepte und ihre Relationen zueinander. Ein Beispiel für die Relation ist: ein Türgriff ist ein Teil der Tür, die Tür ist ein Teil der Karosserie, die Karosserie ist ein Teil des Fahrzeugs. Auch auf diesem Weg lassen sich verschiedene Informationen wie mögliche Fehlerarten, Fehlerorte oder verwendete Bauteile extrahieren sowie die Fehlerklasse des Tickets bestimmen.
Neuronale Netze haben den Nachteil, dass sie noch nicht vollkommen erklärbar sind und damit eine gewisse Unsicherheit in die Ergebnisse bringen. Sie haben jedoch den Vorteil, dass sie auch Entitäten erkennen können, die ihnen nicht antrainiert wurden. Es ist daher nicht notwendig, alle relevanten Fehlerarten, -orte und -bedingungen in allen erdenklichen Schreibweisen im Trainingsdatensatz abzubilden.
Genau das ist der Nachteil einer Ontologie: Sie kann lediglich exakt die bekannten Entitäten extrahieren. Unterscheidet sich auch nur ein Buchstabe, wird diese nicht erkannt. Ihr Vorteil liegt darin, dass sie vollständig nachvollziehbar und damit auch gezielt erweiterbar ist. Zusätzlich ist es hierbei möglich, Relationen und weitere Eigenschaften eines Konzeptes darzustellen. Diese können bei der Extraktion von Wissen hilfreich sein.
Ermutigende Ergebnisse
Zur Evaluierung der von EDAG und denkbares entwickelten Pipeline „AIdentify“ (Artificial Intelligence Identifiy) wurden 1.000 gelabelte Ticketpaare generiert. Dazu sollten drei Benutzer jeweils 100 Testtickets hinsichtlich ihrer Relationen zu zehn weiteren zufälligen Tickets labeln. Zu einem Eingangsticket sollten dann möglichst viele Ticketpaare, die laut Bewertung eine hohe Ähnlichkeit zum Eingangsticket aufweisen, in den ähnlichsten Tickets vorkommen. Als Bewertungsmaßstab der Ergebnisgüte wurden die Faktoren Precision und Recall herangezogen. Die Precision gibt an, wie viel Prozent der ausgegebenen Ticketpaare laut den Benutzern eine Ähnlichkeit aufweisen. Der Recall weist aus wie viel Prozent der Ticketpaare, die von den Benutzern mit einer hohen Ähnlichkeit bewertet wurden, von der Pipeline tatsächlich ausgegeben werden.
Als ein Erfolgsfaktor erwies sich die Darstellung der Tickets: entweder als reiner Text oder als Entitäten (sinngebende Einheiten) mit Fehlerklasse. Im zweiten Fall zeigten sich deutlich bessere Ergebnisse. Spannend war auch die Gegenüberstellung der AIdentify-Pipeline und der Open-Source-Volltextsuche Lucene der Apache Software-Foundation. Im von AIdentify abgedeckten Recall-Bereich von gut 0,2 bis 0,7 zeigten sich fast durchgehend höhere Precision-Werte, in einem kleinen Bereich lagen beide annähernd gleichauf.
In einem dritten Vergleich wurde untersucht, wie sich ontologischer Ansatz und Deep-Lerning-Ansatz unterscheiden. Auch eine Kombination der beiden Analyse-Verfahren wurde mit einbezogen. Das Ergebnis ist relativ klar: Die Ontologie konnte lediglich im Bereich von niedrigen Recall-Werten (<0,27) punkten. Die besten Ergebnisse lieferte fast durchgehend der Einsatz von Neuronalen Netzen, dicht gefolgt vom Kombinationsansatz.
Für den NLP-Einsatz gerüstet
Das Forschungsprojekt „Künstliche Intelligenz zur semantischen Analyse technischer Kurztexte“ (AIdentify) wurde vom Bayerischen Staatsministerium für Wirtschaft, Landesentwicklung und Energie im Rahmen des Bayerischen Verbundforschungsprogramms (BayVFP) zwei Jahre lang gefördert. In dieser Zeit wurden bei EDAG umfangreiche Fähigkeiten rund um Natural Language Processing (NLP) aufgebaut.
Die von der EDAG Group und der denkbares entwickelte Pipeline AIdentify ist nun auf einem guten, funktionsfähigen Stand, der die Bearbeitung verschiedener Anwendungsfälle erlaubt. Auf Basis einer Ticket-Datenbank können beispielsweise ländertypische Fehler an Fahrzeugen, Trends in der Automobilindustrie oder Inkonsistenzen in der Entwicklung eines Fahrzeuges erkannt werden. Darüber hinaus ist durch die modulare Struktur der Pipeline eine Adaption an andere Domänen mit überschaubarem Aufwand möglich. Zentrale Punkte sind eine erweiterte oder neu erstellte Ontologie und die Anpassung der neuronalen Netze. Um die dafür benötigten klassifizierten Daten zu erstellen, können Hilfsprogramme entwickelt werden. Aktuell arbeitet die EDAG Group unter anderem an einer Methode zur semi-automatischen Ontologie-Erstellung.
Falls Sie ein Projekt im Bereich NLP planen oder Fragen zu KI-bezogenen Dienstleistungen von EDAG haben, sprechen Sie mit unserem Spezialisten Heiko Herchet, Vice President Digital Transformation. Weitere Details über die AIdentify-Pipeline, deren Fähigkeiten und Ergebnisse finden Sie in unserem Whitepaper.





