Der Einsatz von Künstlicher Intelligenz (KI) dringt in immer mehr Lebens- und Geschäftsbereiche vor. Spätestens mit der Diskussion um ChatGPT wurde erstmals eine breitere Öffentlichkeit mit der Frage nach der Zuverlässigkeit und Qualität der Ergebnisse einer KI konfrontiert. Doch das Problem wird schon länger erforscht. Denn die Lösungsansätze werden genauso dringend benötigt wie die KI-Anwendungen selbst.
In den vergangenen Wochen machte ein intelligenter Chat-Bot Furore. Mit ChatGPT soll man sich wie mit einem „echten“ Menschen unterhalten können. Die KI ist auch in der Lage, ganze Artikel oder sogar Programmcode zu schreiben, wenn man ihr eine entsprechende Aufgabe stellt. Für Aufregung sorgten vor allem die Schwächen des KI-Modells. Sie brachte nicht nur gelegentlich Fakten durcheinander, sondern erfand einfach welche, inklusive Quellenverweisen, die sich als nicht existent herausstellten oder gar keinen sachlichen Bezug zur damit „belegten“ Aussage hatten.
Das grundsätzliche Problem, das hinter der Geschichte steht, heißt: Kann man einer KI trauen? Was wiederum die Frage aufwirft, inwieweit man die Ergebnisse, die ein KI-Modell liefert, überprüfen oder deren Qualität messen kann. Gerade im Bereich von selbstlernenden Algorithmen, die auf neuronalen Netzwerken basieren, entstammen die Entscheidungen der Künstlichen Intelligenz letztlich einer „Black Box“ – sie lassen sich deshalb nicht ohne weiteres nachvollziehen.
KI erklärbar machen
Neben der wachsenden Nutzung von Machine Learning (ML) wird das Problem durch den starken Anstieg der zur Verfügung stehenden Speicher- und Rechenressourcen verschärft. So wachsen die verwendeten Datenmengen exponentiell, was es immer schwieriger macht, einen Zusammenhang zwischen Input und Output der KI herzustellen.
Doch genau das ist unerlässlich: Transparenz zu schaffen in einem System, das zunächst einmal undurchsichtig ist. Das heißt: aus einem Black-Box-Modell ein White-Box-Modell zu machen, indem Nachvollziehbarkeit hergestellt wird. Nur wenn die Entwickler einer KI wissen, wie das System zu seinen Ergebnissen kommt, können sie gezielt an den entscheidenden Stellen Einfluss nehmen und die Qualität des Outputs verbessern.
Zum anderen gibt es aber auch rechtliche Vorgaben. So verlangt der von der EU-Kommission 2021 verabschiedete Rechtsrahmen für Künstliche Intelligenz, dass Entscheidungen einer KI transparent und nachvollziehbar sein müssen. Damit will die EU verhindern, dass beispielsweise die Ablehnung eines Kredits nicht einfach mit Verweis auf „Kollege Computer“ begründet werden kann.
Verschiedene Wege zum Ziel
In der EDAG Group hat man das Potenzial Künstlicher Intelligenz bereits früh erkannt und befasst sich in ganz unterschiedlichen Bereichen mit der Entwicklung von KI-Modellen für unterschiedliche Einsatzbereiche, wie der Überblick hier zeigt. Einen bedeutenden Anteil nehmen dabei Machine-Learning-Konzepte und Neuronale Netze ein. Insbesondere mit den Bereichen Bilderkennung und -verbesserung, beispielsweise für eine Objekterkennung per Smartphone, und Textanalyse mittels NLP-Verfahren (Natural Language Processing) befassen sich die EDAG-Entwickler intensiv. Letzteres mündete beispielsweise in Projekte wie der Extraktion von Informationen aus Projektbeschreibungen und Lastenheften oder den Wissensschatz in Service-Tickets zu heben.
Zumindest oberflächlich ist die Überprüfung der Ergebnisse eines KI-Modells im Bereich der Bildverarbeitung einfach, denn für den menschlichen Betrachter ist es nachvollziehbar, ob ein Objekt erkannt bzw. richtig klassifiziert wurde. Sprich: Das Soll-Ergebnis ist bekannt, Abweichungen lassen sich problemlos erkennen und damit quantifizieren. Ganz anders sieht es dagegen im Bereich der Textanalyse aus, wo beispielsweise nur schwer zu ermitteln ist, wie viele Service-Tickets aus einer umfangreichen Datenbank tatsächlich für ein bestimmtes Thema relevant sind und zu welchem Prozentsatz das KI-Modell diese gefunden hat.
Im Rahmen ihrer Bachelorarbeit „Explainable Artificial Intelligence for Natural Language Processing“ (kurz: XAI 4 NLP) untersuchte Laura Paskowski bei EDAG verschiedene Ansätze, wie Transparenz bei KI-Modellen im Bereich der Textanalyse hergestellt werden kann. Darüber hinaus befasste sie sich mit der Frage, wie daraus Verbesserungen an den KI-Modellen abgeleitet werden können. Sie beschränkte sich dabei auf lokale Ergebnisse, also die Erklärbarkeit von speziellen Vorhersagen der KI, nicht des gesamten (globalen) Entscheidungsprozesses. Desweiteren lassen sich die Ansätze unterscheiden nach der Frage wie bzw. wann die Erklärung entsteht. „Self-explaining / model-specific“ sind Modelle, die während sie arbeiten gleichzeitig die Erklärung generieren. XAI benötigt in diesem Fall ein Wissen über die inneren Abläufe bzw. die Struktur des KI-Modells. Bei einer post-hoc / model-agnostischen Strategie wird die Erklärung generiert, nachdem das KI-Modell eine Prädiktion erstellt hat. In diesem Fall ist kein Wissen über innere Abläufe und Strukturen des Modells notwendig.
Vier Ansätze in der näheren Betrachtung
Der Ansatz „Local Interpretable Model-agnostic Explanation (LIME)“ beruht darauf, verschiedene Teilergebnisse mit Hilfe sogenannter Surrogate Models, also vereinfachter Modelle, zu erklären und sich darüber dem Gesamtergebnis anzunähern.
Die Layer-wise Relevance Propagation (LRP) setzt auf die Backpropagation des Outputs durch das Netz. Dabei geht man vom Ergebnis aus mehrere Schichten im neuronalen Netz zurück und schaut sich die jeweiligen Relevanzwerte R an. Diese werden durch Aktivierungen und Gewichten berechnet. Auf diese Weise versucht man zum einen herauszufinden, mit welcher Stärke welches Inputwort zur Vorhersage beigetragen hat, zum anderen, welchen Beitrag jedes Neurons auf die Entscheidung hat.
Ein weiterer Ansatz ist DeepLIFT (Deep Learning Important FeaTures). Auch dieser beruht auf einem Zurückpropagieren durch das Netz. Aber anders als bei LRP arbeitet man hier mit Contribution scores für die Neuronen. Diese werden durch gezielte Aktivierungen der Neuronen berechnet, die auf unterschiedliche Eingaben – einem Originalinput und einem Referenzinput – mit unterschiedlichen Ergebnissen reagieren.
Die Entscheidungserklärung mittels Integrated Gradients (IG) beruht auf dem Vergleich einer neutralen Baseline als Input und dem Original-Input. Ausgehend von der Baseline – im Bereich der Bildbearbeitung wäre dies eine schwarze Fläche – werden die Eingaben dem Original-Input langsam angenähert. Auf diesem Pfad wird für jeden Punkt das KI-Modell angewendet und ein Gradient berechnet. Auf Basis eines Integrals der Gradienten entlang des Pfades werden die Integrated Gradients berechnet. Auf diese Weise lässt sich durch Interpolation herausfinden, welche Wörter ausschlaggebend für die Vorhersage des KI-Modells sind.
Anwendung in der Praxis
In einem weiteren Schritt untersuchte Laura Paskowski, wie diese XAI-Ansätze bei der Extraktion von Informationen aus Projektbeschreibungen und Lastenheften mehr Transparenz auf Ergebnisseite herstellen und damit zu einer weiteren Verbesserung des zugrundeliegenden KI-Modells genutzt werden können. Die Aufgabe dieses KI-Modells ist es, aus Projektanfragen oder Lastenheften per NLP zu ermitteln, welche Kompetenzen zentral benötigt werden und auf dieser Grundlage eine Entscheidung zu treffen, welcher Abteilung bzw. welchem Ansprechpartner die weitere Bearbeitung zugewiesen wird. Auf diese Weise sollen Fehlläufe verringert und die Reaktionszeiten gegenüber dem Kunden verbessert werden. 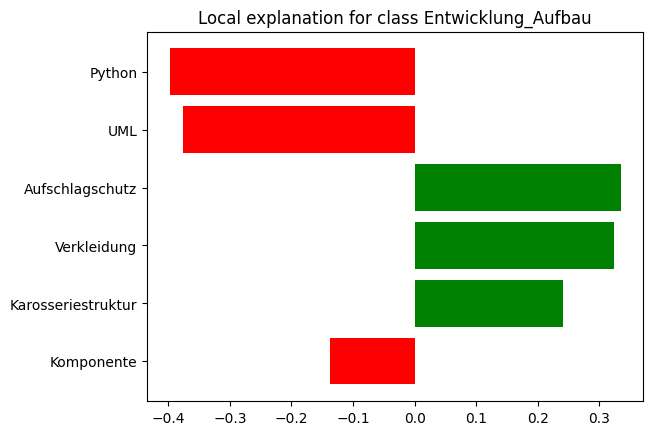
Als Ergebnis liefern die verschiedenen XAI-Ansätze für jede Output-Klasse eine Übersicht von Keywords mit der jeweiligen Gewichtung: hoher Einfluss, geringer Einfluss oder neutral. Diese Gewichtungen sind nach dem Training eines KI-Modells, das auf Machine Learning beruht, zunächst nicht bekannt. XAI ermöglicht es jedoch, die Klassifizierungen der KI in einen „Keyword-Fingerprint“ zu übersetzen, der wiederum darauf überprüft werden kann, ob die darin enthaltenen Keywords bzw. deren Gewichtungen zum erwarteten Ergebnis passen. Auf dieser Basis lässt sich das KI-Modell gezielt anpassen, um die Qualität der Vorhersagen zu verbessern.
Qualität liefern und belegen
Für das KI-Team von EDAG ist es entscheidend, den Kunden nicht nur KI-Modelle für den praktischen Einsatz anbieten, sondern die Ergebnisse auch erklären zu können. Es genügt eben nicht, eine KI zu entwickeln, die zu brauchbaren Ergebnissen kommt. Sondern diese Ergebnisse müssen auch evaluiert werden, um Aussagen über die Qualität treffen zu können. Explainable Artificial Intelligence liefert dazu die nötigen Werkzeuge.
Nur so können Fehlinterpretationen der KI aufgespürt werden, wie sie beispielsweise in einem Experiment zur Unterscheidung verschiedener Tiere aufgetreten waren. Das Modell funktionierte mit den Lerndaten sehr gut, versagte dann aber bei der Eingabe neuer, unbekannter Bilder. Am Ende stellte sich heraus, dass die KI nicht die eigentlichen Objekte – die abgebildeten Tiere – unterschieden hatte, sondern Erkennung nach dem ML-Training lediglich auf unterschiedlichen Hintergründen beruhte, die zufällig mit den jeweiligen Tieren korrelierten.
Und auch für die Weiterentwicklung der Modelle, beispielsweise der Verfeinerung des Inputs, aber auch der Verbesserung des Outputs ist es unabdingbar, die Funktionsweise der KI zu verstehen. Dies dient sowohl dem Vertrauen der Kunden in die Praxistauglichkeit der KI-Modelle, die von EDAG entwickelt werden, als auch dem Vertrauen in die Fähigkeiten der dortigen KI-Experten.
Weitere Informationen zur Anwendung und Qualitätssicherung von KI-Modellen in NLP-Projekten erhalten Sie bei Jacek Burger, Head of Embedded Systems & Computer Vision/AI. Das Whitepaper „Mit KI von der Ticket-Ablage zum Wissensspeicher“ erläutert zudem detailliert, wie KI in einem NLP-Projekt dazu beitragen kann, unerschlossene Wissensschätze im eigenen Unternehmen zu heben. Laden Sie es gleich hier herunter.





